Medical translation challenges and how AI tools can help
Medical translation challenges explained: terminology gaps, regulatory precision, and when AI translation helps versus when human review is non-negotiable.
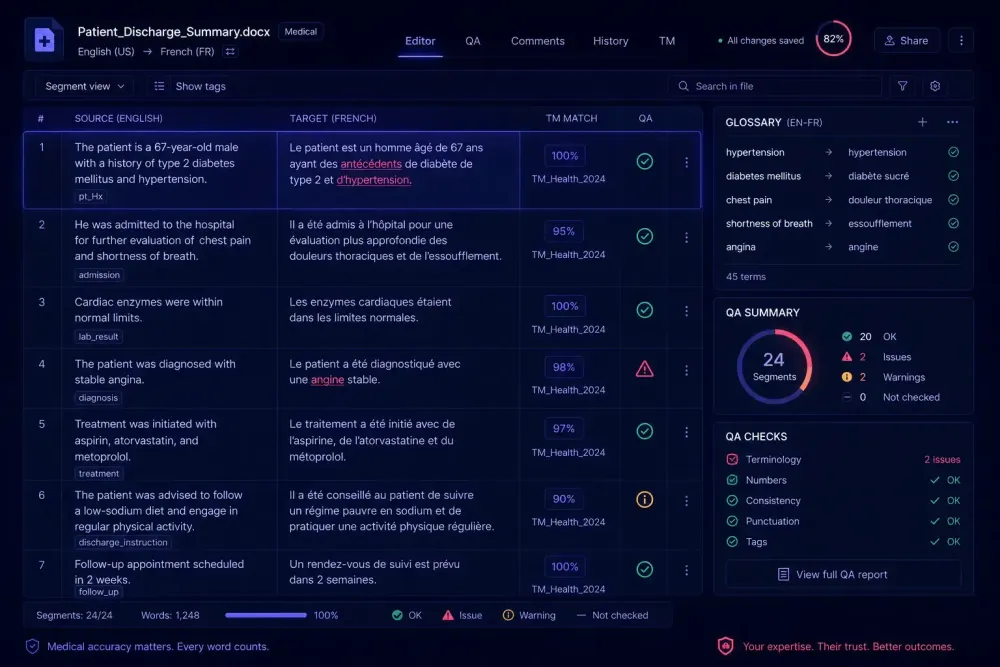
Medical translation is one of the few domains where the gap between "good enough" and "accurate" has direct consequences for patients. A mistranslated medication dosage in a package insert, an ambiguous phrase in a clinical trial protocol, a missing contraindication in a drug label — we've seen all of these create problems at delivery or after it. Working with translation teams across several industries, the feedback from those handling medical content is consistent: the workflow demands are unlike anything else, and generic approaches to quality control fall apart under the specific pressures that medical projects bring.
This is not a post about AI solving medical translation. The realistic picture is more complicated. AI tools have genuine utility in certain parts of the medical translation workflow and real limitations in others. Understanding where that line falls is what helps teams build a process that delivers accurate, reviewable, compliant output regardless of whether the source document is a clinical study report, a drug dossier, or patient-facing materials.
Why medical translation challenges are different from other domains
Most translation domains carry some risk of error. Legal translation has its stakes. Technical documentation has its complexity. Medical translation sits at the intersection of both, with the added layer that errors can have direct clinical consequences.
Several factors make this particularly difficult in practice. Medical language is highly regulated. Terms often carry specific, defined meanings in regulatory contexts that differ from how the same words appear in general clinical communication. "Adverse event" and "adverse drug reaction," for example, are not interchangeable in clinical trial documentation, even though they sound similar to non-specialists. In materials submitted to regulatory bodies, that distinction has to be preserved exactly.
There is also the issue of language pair asymmetry. Some medical terms have well-established equivalents across all major languages. Others don't. For less commonly translated language pairs, translators may encounter source terms with no agreed-upon equivalent in the target language, which creates judgment calls that should be documented and applied consistently across the project.
Source document quality in medical translation is often variable. Internal clinical documents, device manuals, and pharmaceutical reference materials are written by subject-matter experts for subject-matter experts. They use abbreviations, assume domain knowledge, and follow formatting conventions that make sense in their original context but create real ambiguity for translators. A clinical study report that uses "AE" throughout without defining it on first use is a simple example. A device manual that assumes familiarity with ISO 13485 is a harder one.
Where terminology errors actually come from
In our experience working with translation teams, terminology errors in medical content rarely come from ignorance of the medical subject matter. They tend to come from inconsistent application of approved terms, gaps in the reference glossary, and failure to catch problems during the QA stage.
Inconsistent application happens when the same term gets translated differently by different translators on the same project, or by the same translator across sessions without a controlled reference. "Hepatic failure" and "liver failure" may both be defensible translations of the same source term, but in a regulatory dossier they need to be consistent throughout. Without a controlled glossary that constrains term selection during the translation step, these variations reach delivery.
Glossary gaps are harder to prevent because medical terminology expands constantly. A drug dossier for a new molecule will include terminology that doesn't exist in your existing glossary because the compound is new. The teams that handle this best build a pre-translation terminology extraction step into their workflow, reviewing the source document before translation starts and populating the glossary with domain-specific terms before any segments are confirmed. It adds time upfront. It prevents terminology inconsistencies that would otherwise require a full-document review pass after the translation is done.
QA failures happen when QA is treated as a final polish rather than a systematic review. For medical content, QA should include a structured check against the approved glossary, a pass for numeric values (dosages, lab values, timepoints), and a specific pass for omissions where content from the source was not fully rendered in the target. Some of these can be flagged automatically. The human reviewer still needs to understand what they're looking at. Running QA on a medical document without a qualified medical reviewer in the loop is a risk many agencies take without fully acknowledging it.
How medical terminology glossaries differ from general translation glossaries
Building a glossary for a medical translation project is not the same as building one for a legal or marketing project. The structure of the terminology is different, and the stakes are high enough that glossary governance needs to be taken seriously from the start.
A medical glossary for a recurring client relationship should cover several layers: drug names (both INN and brand name, with regional variants where applicable), anatomical terms, clinical outcome measures, regulatory terminology specific to the target market, and product-specific phrases the client uses consistently across their documentation. The product-specific layer is where most glossaries are incomplete. Clients who have been working with the same translation vendor for years sometimes assume the glossary already contains terminology that was added verbally or by email and never formally documented.
For AI-assisted workflows, the glossary becomes more important, not less. AI translation engines can and do substitute synonyms that are technically accurate but not aligned with the client's approved terminology. Without a glossary that constrains term selection during translation, the QA phase has to catch every instance of a term substitution across a document that may run to hundreds of pages. That is slow and prone to misses.
The best medical glossaries we've worked with are structured by document type. A clinical trial protocol glossary looks different from a patient information leaflet glossary because the audience and regulatory context are different. Terms approved for regulatory submissions may be too technical for patient-facing materials, and vice versa. Maintaining separate sub-glossaries for different document types within the same client portfolio is more work to set up, but it pays off when you're managing multiple document types for the same pharmaceutical client.
For a deeper look at how to build and maintain a structured terminology system, our guide on translation terminology management covers the glossary construction process across domains.
How AI translation tools fit into medical translation workflows
AI translation engines have improved substantially. For standard medical prose, including clinical summaries, method descriptions, and background sections with formulaic language, they produce output that gives experienced post-editors a solid starting point. The mechanical work of converting clear, well-structured sentences is handled well. For a clinical study report that runs to hundreds of pages with large amounts of repetitive language, AI pre-translation followed by human post-editing (MTPE) is often the only economically viable path to a high-quality result on a normal project timeline.
Where AI tools struggle is with novel terminology, implicit context, and regulatory precision. A sentence describing a patient's clinical status may be grammatically correct in the target language but miss a clinically significant nuance that only an experienced medical translator would catch. AI output in these situations is not wrong in an obvious way. It is wrong in a subtle way that passes a surface reading and only shows up when a qualified reviewer reads it against the source with clinical knowledge.
What this means in practice: medical translation with AI assistance requires a qualified human reviewer at every output stage. For high-stakes documents submitted to regulators, the review has to be as rigorous as it would be for fully human translation. What AI provides in these cases is speed at the production stage, not a proportional reduction in review effort. Post-editing medical AI output takes longer than post-editing general content, because the reviewer has to verify clinical accuracy at each step, not just grammatical correctness.
For lower-stakes content such as internal training materials, reference documents not submitted to regulators, or draft versions for internal review, the risk profile is different, and a lighter review process may be appropriate. Being explicit about which documents fall into which category before translation starts, and making sure the client understands the different QA levels applied to each, prevents misaligned expectations at delivery.
Managing quality in multi-translator medical projects
Medical translation projects frequently involve multiple translators working simultaneously on the same document or across a document suite. This is a necessity for meeting turnaround times, but it creates specific quality risks the project manager needs to control.
The most common problem is segment-level consistency. When two translators handle different sections of the same document, they make independent term and phrase choices that are each locally acceptable but inconsistent when the document is read as a whole. For medical documents going to regulators or clinical reviewers, this is not acceptable.
The controls that work: a shared, current glossary accessible to all translators on the project, a style guide that specifies how to handle ambiguous cases, and a consolidation review pass after all individual segments are complete but before the document goes to final QA. That last step is what gets skipped under time pressure. And it is exactly where the problems at delivery come from.
Building translation memory into the process is worth the effort. After a medical project is complete and reviewed, confirmed translations go into the TM, and future projects in the same domain pull from that record. Over time this builds up a project-specific consistency base that speeds up QA on subsequent work. It only functions well when the TM is domain-specific and curated: a generic TM with entries from multiple document types and multiple clients is not an appropriate consistency control for medical content.
Clinical, regulatory, and patient-facing content: three different translation problems
One of the decisions that most affects workflow design is understanding which document type is being translated and who will read it.
Clinical content (study reports, investigator brochures, medical monitors' reports) is written for healthcare professionals who will review it with subject-matter expertise. Precision and completeness are the priority.
Regulatory content, meaning submissions to bodies like the EMA or national health authorities, follows specific format and terminology requirements set by the regulating authority. Translators and reviewers need to understand not only the medical content but the regulatory conventions for the target market. A translation of an EU regulatory dossier prepared for a national health authority submission may need to align with specific guidance documents that specify how certain terms must appear in that jurisdiction. This is not something you can verify without someone on the review team who knows that market.
Patient-facing content, including package inserts, informed consent forms, and patient education materials, has the opposite readability requirement. It has to be understood by people without medical training. This is actually harder to translate well than most technical clinical content, because it requires the translator to make active choices about simplification without losing clinical accuracy. AI tools handle this type of translation less reliably than standard clinical prose, because the simplification task involves judgment that does not reduce to learned patterns.
Understanding which category a project falls into determines which review process to apply, which glossary to use, and what QA criteria to hold the output to. Teams that treat all medical content as a single category reliably run into problems at delivery.
Building a repeatable medical translation process
The teams that handle medical translation well treat each project as an instance of a documented process. The implication is that the process documentation — the glossaries, the style guides, the QA checklists, the reviewer qualification requirements — actually exists and is maintained, not just assumed.
One area that consistently gets underfunded is reviewer qualification. For medical translation, the review cannot be done by a generalist. The person checking medical AI output needs enough clinical familiarity with the document type to catch the subtle errors. That often means working with freelancers who have both language and subject-matter credentials, which limits the pool and raises costs. Factoring that into project pricing upfront, rather than discovering it at the review stage, is what separates agencies that sustain medical translation work from those that pick it up occasionally and find it unprofitable.
For translation agencies entering or growing within the medical domain, the practical priority is building the documentation layer before taking on large projects. A glossary that covers common terminology for your primary client, a QA checklist calibrated to the document types you handle most often, and documented review criteria that reviewers can apply consistently are what makes medical translation scalable. Without them, quality depends on individual translators remembering the same things across every project. That works until someone is unavailable or handling an unfamiliar document type.
For teams starting with AI-assisted medical translation: run a pilot on a document type where errors are recoverable. Document what the AI output gets right and wrong in your specific domain and language pair. Calibrate your glossary and review process based on that experience before scaling to higher-stakes documents.
For a broader look at how domain expertise shapes translator selection and workflow design, our piece on domain specialization in translation covers how to match the right expertise to the right project across medical, legal, technical, and other domains.