How to Build a Translation Workflow That Scales From 1 to 10 Language Pairs
How to scale a translation workflow from 1 to 10 language pairs without losing quality. Practical guidance on terminology, file handling, QA, and AI integration.
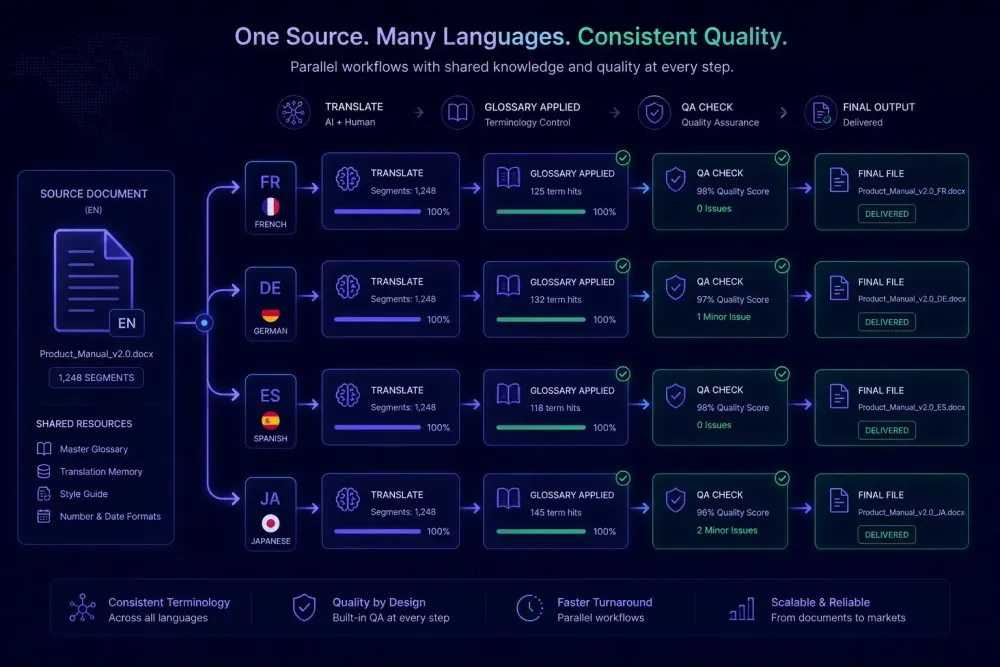
Most agencies don't plan to run ten language pairs. They start with one, get good at it, add a second when a client asks, and at some point they're managing seven pairs with a workflow that was never designed for that kind of load. Translation workflow scaling is less about growth ambitions than about preventing the cracks that appear when you add languages to a system built for fewer. The cracks are predictable. So is the fix.
Why translation workflow scaling breaks informal systems
One language pair can run on informal systems. The project manager knows the translator, the translator knows the client's style, and most coordination happens in messages between people who've worked together for months. Add a second pair and you add a translator who doesn't share that history. Add a fifth and you have a PM tracking six translators across four language combinations, none of whom know what the others have agreed to.
Terminology is the first thing to drift. The Spanish team translates a product feature one way. The French team, working from the same source, picks a different word. The client receives a multilingual brochure with two terms for the same thing. This isn't a translation error — it's a coordination failure, and it happens specifically because the terminology decision that existed informally in one pair wasn't documented anywhere a second pair could find it.
File handling follows close behind. Naming conventions that worked for two pairs become ambiguous when you're processing the same source document into eight target languages. contract_final_v2.docx is fine when there's one language. When there are eight, it creates problems.
The deeper issue is that most single-pair workflows are held together by familiarity, not documentation. The moment you add a pair, you're adding a translator who doesn't share the institutional knowledge that accumulated over months. Translation workflow scaling requires externalizing what previously lived in someone's head: terminology decisions, client preferences, file conventions, quality standards. This doesn't mean rebuilding everything at once — it means identifying which parts of your workflow are universal and which are language-specific, because the universal parts are what you can standardize as you grow.
What to document before you add the next pair
The highest-return thing you can do before adding a language pair is to write two documents: one covering what applies to this client regardless of target language, and one capturing the terminology that cannot vary across outputs.
The first — a client brief — covers tone and register, formatting requirements for the delivery format, and the client's definition of acceptable quality. It should be short enough that a translator actually reads it. One page, three sections. None of this is language-specific, which means every new pair benefits from the same document.
The second is a source-language term list with definitions. Not target translations (those vary by pair), but the source terms and what they mean in context — enough that a translator who doesn't know the domain can apply them correctly. A pharmaceutical client's "indication" isn't the everyday word. A software company's "integration" might have a precise meaning in their documentation. The source-language definition is what anchors all the target glossaries, and you build it once rather than separately for each pair.
We've seen this play out directly. An agency running technical manuals for an industrial manufacturer grew from two to six language pairs over eight months. For the first three months of that expansion, the PM spent most of their time firefighting consistency errors across pairs. After they built a single client brief that all translators received regardless of language, error rates dropped and onboarding a new pair became a half-day job rather than a week of coordination.
This is also one of those places where the effort feels disproportionate until it saves you. A two-hour investment in documentation before adding a pair costs less than one round of client revisions after delivery.
How file structure holds up under real volume
At one language pair, file handling is mostly fine however you do it. At six, it breaks. The common failure mode: files named for the content rather than the language, versions saved in a shared folder without structure, and a PM who has to open each file to figure out which language and stage it represents.
The structure that holds at scale separates files by language pair from the first step, not at delivery. A folder per client, a folder per project inside that, a folder per language pair inside that. This makes it immediately clear where a file is in the process and which language it belongs to.
Naming conventions matter more with volume. A format like [client]_[project]_[date]_[lang-pair]_[stage].docx takes thirty seconds to apply and removes most of the "wait, which version is this" confusion. Something like acme_q2manual_2026-05_EN-DE_pretranslation.docx is interpretable to anyone on the team, including someone who joined the project mid-stream.
For CAT-based workflows, the project structure should mirror the file structure. If you're running eight language pairs as separate CAT projects, project names and TM assignments should follow the same convention. A shared TM across language pairs creates a specific risk: a Spanish fuzzy match appearing in a French segment looks plausible enough that a translator might accept it without checking, and the error is hard to catch in QA because it reads fluently.
Our article on batch translation covers the infrastructure for handling multiple files efficiently.
Terminology: build the infrastructure before you need it
The agencies that handle terminology well at scale share one thing: they built the infrastructure before a client complained, not after. Once a terminology inconsistency has made it into a delivered document, the response is reactive. Building the glossary before adding the pair is faster and cheaper.
A scalable glossary setup has two layers. First, the source-language term list with definitions — built once per client and maintained centrally. Second, a target-language glossary for each pair, derived from the source list and reviewed by someone who knows both the domain and the target language. When a source-language definition changes, you know exactly which target glossaries need updating.
The full setup is covered in our terminology management guide. The practical advice here is: don't wait for the glossary to be complete before putting it to use. Fifteen well-defined terms covering the most critical product vocabulary is more useful than a hundred entries nobody has reviewed. Build the critical terms first, add over time.
The workflow around the glossary matters as much as the glossary itself. Translators need a way to flag terms that aren't covered, and someone needs to be responsible for resolving flagged terms within the project cycle — not after delivery. CAT-tool terminology enforcement earns its value precisely here: when the editor surfaces a source term in a segment that has no glossary match applied, it catches drift before it reaches the client.
Agencies that skip this process tend to discover their terminology problem when a client notices it. At that point, you're correcting existing documents while simultaneously building the glossary that would have prevented the error. Doing both at once under deadline pressure is genuinely painful, and it's entirely avoidable.
When AI pre-translation fits into a multilingual workflow
AI pre-translation changes the economics of multilingual work, but it doesn't change the dependency order. The quality of AI output depends heavily on the context it receives: domain, glossary terms, style instructions. A general prompt applied to technical content produces general output. A prompt with domain context and the client's approved terminology produces output a post-editor can work through meaningfully faster.
The sequencing issue we see repeatedly: agencies add AI pre-translation before the terminology infrastructure is in place, find the output less consistent than expected, and attribute the problem to the AI. In most cases the model is doing what it can with what it received. The fix is upstream, not in the model settings.
In a multilingual workflow, AI pre-translation tends to perform best at the highest-volume, most predictable language pairs first. The pair with the most historical data, a settled glossary, and consistent source content is where to test before expanding. When the configuration works well for one pair, rolling it out to additional pairs is largely a matter of building out target-language glossaries and handling any language-specific formatting requirements.
This is also where the preparation steps pay off in a second way. A well-defined glossary doesn't just help human post-editors — it's what allows an AI prompt to produce domain-specific output rather than generic approximations. The two investments compound.
For agencies that want a structured AI translation step for DOCX files without rebuilding their CAT workflow, SnapIntel handles this: you upload your DOCX, configure a glossary and translation prompt, run the job, and download the translated DOCX alongside an Excel export you can use to populate your TM in any CAT tool. It works best when the source content is consistent and the terminology is already defined — which, if the earlier steps are in place, they are.
QA at scale: what changes when you're running many pairs
With one language pair, a reviewer can work through translated output against the source. With ten, that approach breaks down. You'd need a qualified reviewer in each target language reviewing each output before delivery. Most agencies don't have that capacity for every project.
The practices that hold up at scale are ones that can be applied independently within each pair. A QA checklist the translator or reviewer completes before delivery, specific to the project and language pair. Automated checks for number formatting, punctuation consistency, and glossary coverage — things that don't require human judgment and can be flagged programmatically. A clear process for terminology questions that doesn't require the PM to intervene every time.
The PM's role shifts as scale increases. With two pairs, a PM can review output meaningfully. With eight, that's not realistic. The role moves from reviewing content to managing process: are QA steps being completed, are errors being logged, are flagged terms being resolved within the project cycle?
One thing agencies consistently underinvest in at scale is the post-delivery error log. When a client sends feedback, it's useful to know whether the same type of error appears consistently in a specific language pair, with a specific translator, or in a specific document type. Without logging, you fix the same class of errors repeatedly without identifying where they originate. A simple per-project, per-pair log with error category and whether the error was caught before or after delivery is enough to surface patterns over time.
This doesn't apply if your projects are highly variable in content and team composition — in that case, patterns are harder to isolate. But for agencies running the same client's content across multiple pairs on a recurring basis, the log is what makes improvement systematic rather than reactive.
Actionable takeaway
Before you add a language pair, document the client requirements that apply regardless of target language and the terminology that cannot vary across outputs. Get both into a format any translator can use from day one. The operational work — file naming, CAT project structure, AI pre-translation workflow, QA checklists — builds on top of that foundation. Starting with the operational pieces before the documentation foundation is in place is what produces the growing pains most agencies attribute to scale, but are really just undocumented systems catching up with them.