AI Translation Agents Explained: How RAG and LLM Routing Are Changing Document Translation
AI translation agents use RAG and LLM routing to coordinate translation pipelines. Here's how each technique works and where it actually makes a difference.
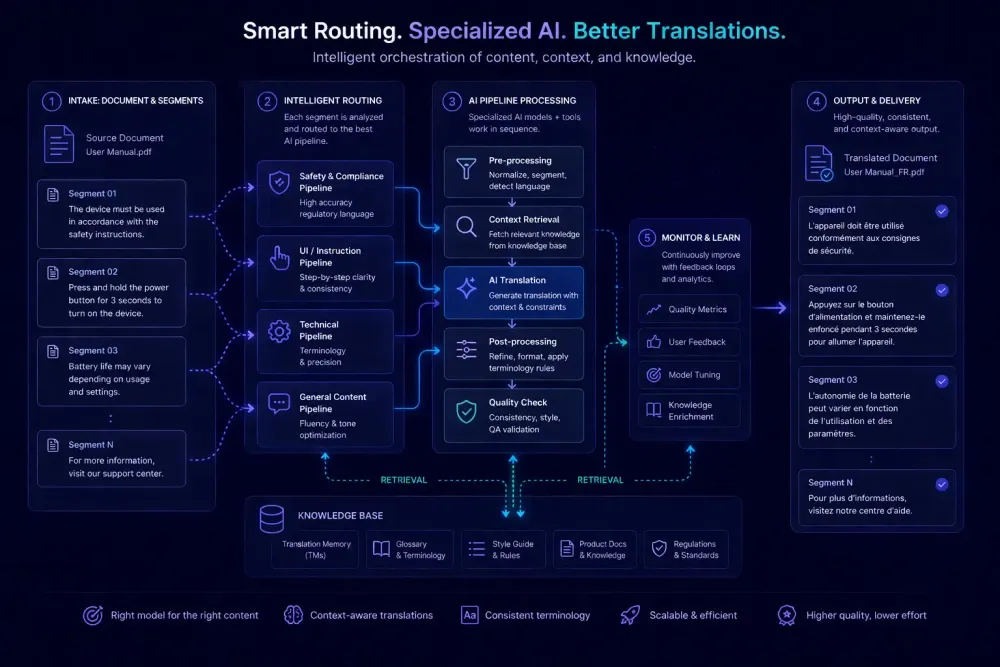
The phrase ai translation agents has made its way from AI research papers into product announcements faster than most translation professionals expected. Where AI translation once meant a single model taking source text and returning a target, more workflows now involve an orchestrated sequence of steps: file parsing, context retrieval, translation, quality checking, and output formatting, each handled by a separate automated process. That pipeline is what the industry increasingly calls an agent. Some of this labeling is marketing. But two technical ideas underneath the shift are worth understanding on their own terms: retrieval-augmented generation (RAG) and LLM routing. Neither is magic. Both affect document translation quality in ways that matter when you're choosing tools or pricing AI-assisted projects.
What an AI translation agent actually is
In a conventional machine translation setup, a single model takes a source segment, processes it, and returns a target segment. The model's behavior depends entirely on what it learned during training. If the source text uses specialized terminology the model hasn't encountered, it makes substitutions that range from passable to quietly wrong.
An AI translation agent replaces that single step with a pipeline. A document moves through several automated processes before, during, and after translation: one analyzes the document's domain, another queries a glossary or translation memory, the translation step may involve one or more models with different characteristics, and a final pass runs automated QA checks before the file is assembled. The whole thing happens without manual reconfiguration between documents.
The practical effect is that a technical manual and a marketing deck can trigger different retrieval steps, different model choices, and different QA criteria automatically. A segment with a 100% TM match bypasses the AI model entirely. A segment with no match gets routed to the appropriate model. A segment that fails a QA rule gets flagged before delivery. None of this requires a person to decide at each branch.
This isn't entirely new territory. CAT tools have long combined translation memory lookup, glossary matching, and machine translation in a single interface. What's changed is the automation level. An agent makes decisions about workflow steps that used to require a project manager or translator to handle manually. That shift is real. The term "agent" borrows from AI research, where it describes a system that perceives its environment, takes actions, and pursues goals over multiple steps. Most translation agents in practice are simpler than that framing implies. They follow predefined pipelines rather than reasoning from scratch. The gap between the marketing framing and the actual architecture is where useful evaluation starts.
How RAG works in a translation context
RAG stands for retrieval-augmented generation. Before generating output, the model retrieves relevant information from an external source and uses that information as part of its input. The output reflects both the model's general language capability and the retrieved context.
In translation, this typically works as follows. Before translating a segment, the system queries a knowledge base — a client glossary, a translation memory, previous documents in the same domain — and injects the most relevant results into the model's context alongside the source text. The model translates using both its language knowledge and the retrieved terms.
The difference is most visible in terminology-heavy content. Without retrieval, a model translating a pharmaceutical regulatory document will draw on terminology from its training data. With retrieval, the system can look up the client-approved term for a specific drug compound and pass it to the model before translation starts. The model is more likely to use the right term because the right term is literally part of the input.
We've run this comparison on long-form technical documents: a 50-page regulatory report with consistent references to specific instrument names, reporting categories, and legal entity classifications. RAG-assisted translation held terminology alignment noticeably better than the same model without retrieved context. The improvement wasn't uniform across the document. It concentrated in the segments where approved terms existed in the knowledge base and retrieval actually fired.
That caveat is worth sitting with. RAG quality depends entirely on what's available to retrieve and whether the retrieval step selects the right context. An outdated glossary retrieved with confidence can actively hurt accuracy — the model follows the retrieved terms even when those terms are wrong. A glossary assembled for a previous project and never updated is worse than no retrieval at all in some cases. A strong RAG implementation needs a well-maintained knowledge base and a retrieval strategy that knows when not to retrieve.
There's also the question of retrieval mechanism. Exact-term matching works well for controlled terminology lists but misses related context when the source segment uses a synonym or reformulation. Semantic retrieval surfaces relevant material even when the exact term doesn't appear, but requires more infrastructure. The practical difference shows up most in technical content where terminology varies in phrasing but not in meaning.
LLM routing: matching the model to the task
LLM routing means the system selects which model to use based on properties of the input rather than sending every segment through the same model.
Translation workflows contain a wide range of content. An internal FAQ, a patent claim, a social media post, and a 200-page engineering specification differ in complexity, domain specificity, and acceptable error rates. Routing the most powerful and expensive model through every segment adds cost without proportional benefit. Routing a weaker model through everything saves money but introduces errors in exactly the segments where quality matters most.
Routing addresses this by analyzing incoming content and directing it to an appropriate model or configuration. Implementations vary. Some systems route based on segment length. Others classify the domain automatically and route on that classification. Others run a fast preliminary pass and send low-confidence segments to a more capable model for a second attempt. The specifics of the routing logic determine how much benefit you actually get.
The structural logic resembles how CAT tools handle translation memory: 100% exact matches are applied automatically, fuzzy matches go to a translator for review, untranslated segments get an MT suggestion. Routing extends that tiered handling to the AI layer, where the tiers correspond to model choice and generation budget rather than TM confidence level.
For agencies, the cost implication is real. A routing configuration that correctly identifies which segments need careful processing and which don't can reduce per-project AI spend while maintaining output quality where it matters. The failure mode is misconfiguration: a short but complex legal clause routed to a fast, lightweight model because of its length rather than its content produces exactly the kind of error that bypasses automated QA and arrives at the client intact.
Where agents genuinely improve output quality
Agent-based workflows produce the clearest improvement in two situations.
The first is documents with heavy, client-specific terminology requirements. When retrieval runs before translation and approved terms are injected into context, the output starts from a more accurate terminology baseline. A medical translation project involving clinical study documentation benefits from a system that retrieves and applies approved drug names, dosage formats, and endpoint definitions before generating any target text. Without that step, the model draws on training-data terminology, which may or may not match what the client has approved.
The second is batch workflows where automated QA has to run at scale. An agent that checks each translated segment against glossary requirements, flags number format mismatches, catches missing markup tags, and identifies target-source length ratios outside acceptable bounds does work that would otherwise fall to human reviewers. It doesn't eliminate the need for post-editing. It surfaces the rule-based, detectable problems first, so a human reviewer can spend time on judgment calls rather than on obvious errors any automated check could have caught.
A third situation worth mentioning, though discussed less often: documents where formatting structure matters as much as translation accuracy. An agent that detects whether it's working with a table, a bulleted list, or running prose — and adjusts its output handling accordingly — produces fewer layout problems in the assembled DOCX. This doesn't make the agent a formatting tool, but it reduces cleanup before delivery.
Outside these situations, the agent architecture doesn't necessarily produce better output than a simpler approach. Short documents, general content, and language pairs where the model's training data is dense often translate accurately without multi-step orchestration. Adding five pipeline steps to a two-page internal memo is overhead, not improvement.
What the limitations look like in practice
Multi-step pipelines add control points. They don't change the fundamental constraints of AI translation.
Context window limits still apply. A RAG step retrieves terminology and injects it into context, but a long document creates coherence challenges that segment-level retrieval doesn't fully solve. A term introduced in section two of a 60-page technical manual may not carry through consistently to section thirty unless the system explicitly tracks running document context — which most implementations don't do automatically.
Retrieval quality depends on the knowledge base. When the glossary is thin, retrieval finds nothing useful and the model falls back to training-data defaults. When the glossary is outdated, retrieval finds confident but wrong answers. A weak or unmaintained knowledge base doesn't just fail to help — it can introduce errors that look authoritative because they came from an approved source.
Routing requires someone to define the logic and maintain it as model options change. This is engineering work that sits upstream of the translation workflow, but it directly affects output quality in ways that don't always surface in QA reports.
The agent label, in short, doesn't tell you whether a tool is good. It tells you the tool is more complex than a single model call, with more control points and more potential failure points. Evaluation has to go step by step.
How to evaluate a tool that claims to use agents
When a vendor describes their product as an AI translation agent, useful questions are specific ones.
Ask what the system retrieves before translation starts. If the answer involves a glossary or translation memory, ask whether matching is exact or semantic. Exact matching works for controlled term lists. Semantic retrieval surfaces relevant context even when the precise term isn't in the source segment. Both have valid applications, but they perform differently on different content types.
Ask how routing decisions are made. A concrete answer will name the criteria: segment length, domain classification, confidence scoring from a preliminary pass. A vague answer — "the AI selects the best model" — usually means there's no meaningful routing. One model handles everything.
Ask what the automated QA step specifically checks. A well-designed QA pass at the segment level catches enumerable issues: glossary term violations, number mismatches, missing markup tags, source-target length ratios outside acceptable bounds. A quality score with no definition of what it measures tells you little about whether the output is ready for delivery.
We also recommend testing with your own content before committing to a workflow. Tools often behave very differently on technical documents versus general content, and on language pairs they were optimized for versus others. That gap rarely shows up in vendor documentation.
If explicit control over the context going into translation is part of what you need, the preparation layer matters as much as the translation step itself. SnapIntel is built around a preparation-first workflow: glossary and prompt inputs are visible, editable, and require explicit approval before any translation runs. For translators and agencies who want to know exactly what context the model is working with, that kind of transparency is worth looking for in any agent-based tool you evaluate.
What this means for your team
There's a real difference between a tool that returns a translation and one where you can see what context the model used, why it went to that model, and what the QA step actually checked. That transparency is what the agent architecture can provide. It doesn't always, but when it's designed well, it moves AI translation from a black box toward something you can actually audit and improve.
That shift comes with a corresponding responsibility for what you put into the system. Your glossary and translation memory become the foundation of your retrieval quality. If they're maintained well, agent-based tools perform better with them. If they're thin, outdated, or assembled once and never revisited, no routing sophistication compensates for weak source data.
We've written about how AI translation is changing the day-to-day work of translators more broadly in this piece on how the field is shifting in 2026. If you're still sorting out where agent-based tools sit relative to conventional MT and AI-assisted translation, the distinctions between those categories are worth understanding before you evaluate any specific product — we covered them in this comparison.
For post-editors, the shift to agent pipelines changes what errors look like. Rather than being randomly distributed across a document, errors from a misconfigured agent tend to cluster around specific failure modes: wrong retrieved terminology, routing errors on a particular content type, QA rules that don't cover the document structure in question. Recognizing those patterns makes post-editing faster and makes it easier to give feedback that actually improves the workflow over time.
Actionable takeaway
Before committing to any tool that claims to use AI agents, RAG, or intelligent LLM routing, test it with your own glossary on a document from your most terminology-dense domain. Ask three specific questions: what does the system retrieve before translation starts, how does it make routing decisions, and what does the automated QA step specifically check. The answers to those questions will tell you more than any benchmark figure or product summary.