DeepL API vs OpenAI API vs Google Translate: Which Translation Engine Should Agencies Use?
A practical comparison of DeepL API vs OpenAI translation API vs Google Translate for agencies — quality, pricing, language coverage, and workflow fit.
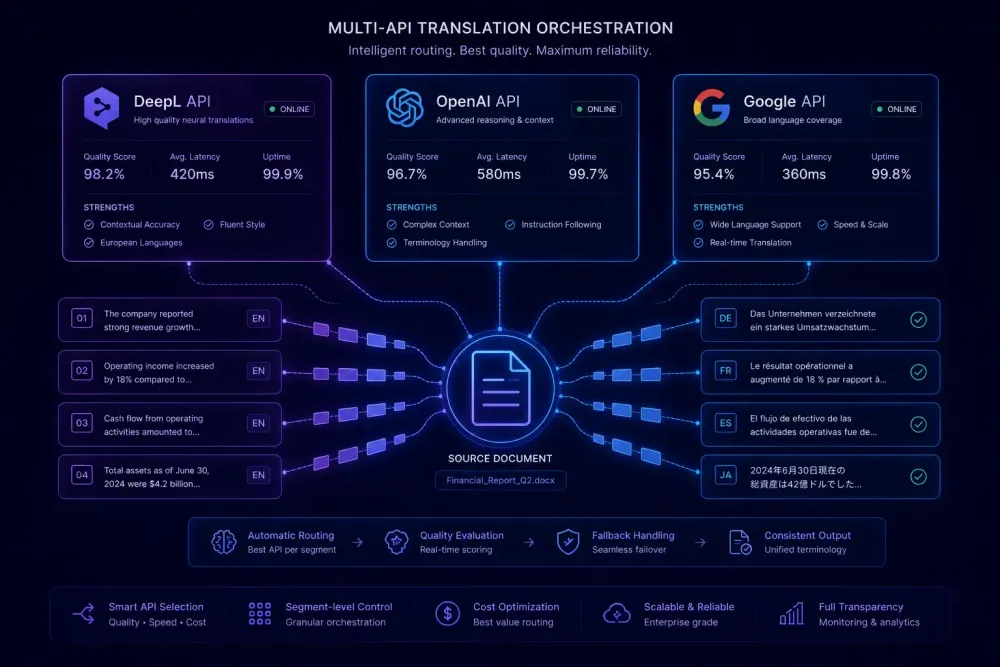
When agencies ask us which translation API to build on, the honest answer is that the DeepL API vs OpenAI translation API debate alone divides opinion in ways that don't map cleanly to objective performance data. Add Google Translate to the comparison, and you have three production-ready, mature options that each make sense for specific workflows — and each fails in ways that aren't obvious until you're six months into a production integration. This post covers what we've learned about where each engine actually performs, how the cost models work at agency volumes, and how to make the choice without regretting it.
What each API was actually built to do
DeepL is a dedicated neural translation engine. The training data, architecture choices, and evaluation criteria all optimize for translation quality, specifically for European language pairs where it has the deepest coverage. The API surface reflects this: you pass text and a language pair, you get back a translation. The glossary feature lets you register approved term pairs per project. The document translation endpoint accepts DOCX, PPTX, HTML, and PDF and returns a formatted translated file. Minimal configuration is a deliberate choice, not a limitation.
Google Cloud Translation API was built for breadth and throughput. It runs on Google's Neural Machine Translation system and covers more than 130 languages, including low-resource languages that no other major translation API touches. The Advanced tier adds AutoML model adaptation, structured glossary management via XLIFF input files, and batch document translation with Cloud Storage integration. This is enterprise infrastructure designed for enormous volumes across highly diverse language combinations, and the pricing tiers and SLA structures reflect that.
OpenAI's API, via GPT-4o or similar models, is not a translation API. This distinction matters more than it might seem. It's a general-purpose language model that you instruct to perform translation. The prompt can include a full glossary, domain description, tone requirements, formatting conventions, and any other context you choose to pass. That flexibility produces a higher quality ceiling for domains that benefit from precise contextual instruction. But the model has no inherent knowledge it's acting as a translation tool until you tell it so, and you're responsible for every prompt structure and context layer you build and maintain.
Language coverage — when geography decides the choice
If your agency handles translation into languages outside Europe, this question often settles the engine comparison before any quality discussion starts.
DeepL's current language list sits around 30 languages. For agencies focused on EU markets, English into French, German, Spanish, Portuguese, Polish, Italian, or Dutch, that coverage is sufficient. For anything beyond that range, you'll need a different engine or a hybrid setup.
Google Translate API covers more than 130 languages. This includes Central Asian, Sub-Saharan African, and Southeast Asian languages that aren't served by other major translation APIs at scale. For agencies with clients in markets like Kazakhstan, Nigeria, or Vietnam, Google is often the only practical choice for a production pipeline.
OpenAI models are broadly multilingual, but performance varies considerably by language. High-resource languages with large training corpora — French, German, Japanese, Chinese — tend to produce quality output with reasonable prompting. Lower-resource languages are more variable. We've seen GPT-4o produce noticeably uneven output in Kazakh compared to its Spanish output, even with identical system prompts. That doesn't disqualify OpenAI for those language pairs, but it does mean a quality review step can't be skipped.
One thing worth saying plainly: "language coverage" doesn't just mean the API accepts a request in a given language. It means the output quality meets a usable threshold for professional delivery. Google's 130+ language count includes some pairs where quality is significantly lower than its European pair performance. Testing your specific language pairs with representative content is the only reliable way to know what you're buying.
DeepL API vs OpenAI translation API: quality differences that matter
"Which is highest quality?" is the wrong question. Quality depends on content type, language pair, and how much configuration you apply. Here's where the differences actually show up.
In legal and technical documents — contracts, compliance materials, specifications — terminology precision matters more than fluency. DeepL's glossary enforcement is straightforward within its supported language range: register term pairs per project, and the engine attempts to apply them consistently. Google Cloud Translation Advanced supports structured XLIFF glossary inputs and handles terminology reliably once configured. OpenAI lets you inject a full glossary with usage context and domain instructions in the system prompt, which gives the most control. That prompt needs to be designed, tested, and maintained as terminology evolves.
A concrete example: a 5,000-word supplier contract translated from English into German. DeepL typically produces output in German legal register that requires less post-editing than Google NMT on the same document. Run the same contract through GPT-4o with a legal domain glossary and a system prompt specifying German business formal register, and the output can match or exceed DeepL quality — but that prompt needs to be built and maintained. If your agency handles a steady flow of German legal documents, the investment pays off. If it's one project every few months, it probably doesn't.
For marketing and brand content, product descriptions, campaign copy, and website pages, fluency alone isn't sufficient; register and voice matter. OpenAI handles this better than either dedicated translation engine because you can describe brand tone in the prompt and provide examples of approved phrasing. DeepL tends to produce grammatically correct but register-neutral output. Google NMT output for marketing content typically requires transcreation work before delivery.
For high-volume commodity translation, large batches of product strings, internal documentation, and support articles, quality requirements are lower and throughput matters more. Google Translate API handles this category reliably and at lower per-character cost than DeepL at comparable volumes.
This doesn't apply uniformly. We've worked with agencies that run everything through OpenAI regardless of content type because their clients are in regulated industries and want domain glossary compliance baked into every job. The content category generalizations above are starting points, not rules.
Pricing — what agencies actually spend at production scale
Pricing comparisons across these APIs require some translation of their own, since the billing models are different.
DeepL API Pro charges per character. Standard pricing runs approximately $25 per million characters, with volume pricing for enterprise tiers. Document translation is billed separately from plain-text API calls. There's a free tier capped at 500,000 characters per month, useful for evaluation but not production volume.
Google Cloud Translation API also charges per character. The Basic NMT tier runs approximately $20 per million characters. Advanced features, AutoML, batch processing, and document translation, add cost and vary by feature and volume. For most agency production pipelines, the per-character rate is competitive and often lower than DeepL at comparable throughput.
OpenAI API billing is per token, not per character. One token is roughly 3–4 characters of English text, though this varies by language and script. GPT-4o is currently priced at $2.50 per million input tokens and $10 per million output tokens. For a translation task, output length is roughly equal to input — so a document around 500,000 characters runs to about $3–5 in direct API costs, competitive with DeepL at standard pricing. But the actual cost depends heavily on how much context is in the system prompt. A prompt with a 400-word glossary and 200-word domain instruction adds meaningful overhead multiplied across thousands of segments in a batch job. Agencies running OpenAI-based translation at scale need to model prompt overhead in their cost projections, not just the source text token count.
One cost that doesn't appear in any pricing table: the operational cost of maintaining translation infrastructure. A DeepL or Google Translate integration can be operational in days. An OpenAI-based document translation pipeline with proper glossary handling, segmentation, progress tracking, QA artifact generation, and output assembly typically takes weeks to build and ongoing engineering time to maintain. That cost is real and belongs in any honest budget comparison.
Document workflow fit — what the API needs to do in production
API quality matters for text output; what the API returns as a deliverable matters for client work. These are different questions.
DeepL's document translation API accepts DOCX, PPTX, HTML, and PDF and returns a translated document. Formatting preservation for DOCX is reliable for standard business documents. What the API doesn't return is a bilingual output or a source/target spreadsheet for TM population. The artifact is a translated file, not a translation memory entry.
Google Cloud Translation API supports document translation for DOCX and PDF with reasonable formatting handling for standard documents. Batch translation endpoints allow submitting multiple files with results written to Cloud Storage. Like DeepL, the output is a finished translated document rather than a structured bilingual artifact ready for TM import.
OpenAI has no document translation endpoint. Segmentation, context packaging, API calls, and output assembly are all your responsibility — in code or via a workflow layer you build or adopt. Agencies building an in-house OpenAI document translation pipeline often spend more engineering time on infrastructure than on prompt quality. That's not a knock on OpenAI; it's an accurate description of what it takes.
For agencies that want context-aware, prompt-driven translation quality on DOCX and XLSX documents without building the underlying pipeline, structured workflow tools handle this at the application layer. SnapIntel manages document segmentation, glossary and prompt configuration, translation job execution, progress tracking, and delivery artifact assembly — translated DOCX, neutral XLSX export, and QA report — on top of your own OpenAI key (BYOK). Whether that's the right trade-off depends on your engineering capacity and how much of the translation stack you want to own. For agencies without in-house developers, a managed workflow layer is usually a faster path to production. For agencies with strong engineering teams, building on the raw OpenAI API gives more control over every step.
How agencies actually mix engines in production
The cleanest production setups don't commit to one engine across all project types. They route by content type or language pair.
A configuration we see often: Google Translate API handles first-pass translation for high-volume commodity content and for language pairs outside DeepL's coverage. DeepL handles premium European language pair projects where output fluency directly affects post-editing cost. OpenAI handles high-stakes documents — legal agreements, branded marketing materials, regulated content — where domain precision justifies the setup overhead.
The routing logic doesn't need to be complex. Many agencies manage it through a simple project intake configuration: content type maps to engine, language pair constrains the choice if DeepL doesn't cover it, and the project manager confirms before the job starts.
This works best when intake is predictable and content types are consistent. It gets messy for agencies with highly variable content where routing decisions would be made ad hoc per document. Managing three separate API integrations without consistent routing logic adds operational overhead that can cancel out any quality gains.
A note on timing: the engine comparison above will shift as model capabilities evolve. DeepL has been expanding its language coverage steadily. OpenAI releases updated models regularly. What's true about relative quality today may not hold in six months. That's one more reason to build workflow flexibility into your stack rather than committing deeply to a single engine. If you're curious about how AI translation tools are reshaping the broader workflow for translators and agencies in 2026, the pace of change there is fast enough that staying flexible pays off.
How to make the call for your agency
Language coverage comes first. If your primary language pairs fall within DeepL's 30 languages and you need a translation-first API with minimal setup, DeepL is the most straightforward path. If you regularly need language pairs outside that range — Central Asian, African, Southeast Asian — Google Translate API is the practical default.
Quality requirements come second. If you're delivering final documents in high-stakes domains where contextual instruction matters, OpenAI produces the best ceiling quality for supported languages, provided you have the capacity to build or procure the workflow infrastructure around it.
Then check the cost model against your actual volumes. Per-character pricing from DeepL and Google is predictable and easy to model. OpenAI per-token pricing is competitive but requires accounting for prompt overhead, which varies by how much context you inject. Run the numbers for your top three project types before committing to an enterprise tier on any platform.
One recommendation we'd stand behind regardless of engine: don't evaluate these APIs on generic demo content. Pull 20 representative documents from your actual project archive, run each through all three engines in your primary language pairs, post-edit each to delivery quality, and time the work. The time-to-delivery-quality number for your specific content is the metric that predicts actual production cost. That exercise has shifted agency decisions more often than any benchmark comparison we've seen. It also reveals which engine fails on your content types before you've built anything around it.