AI translation tools are changing the way translators work in 2026
AI translation tools are now part of ordinary production in professional translation. That sentence would have sounded premature a few years ago. In 2026, it feels plain.
AI translation tools are now part of ordinary production in professional translation. That sentence would have sounded premature a few years ago. In 2026, it feels plain. The change is not that AI can draft a segment. The change is that translators and agencies now have to decide where AI fits inside a CAT tool, a TM, a glossary, a QA report, and a delivery process that still depends on trust. ELIS 2025 says machine translation is used in more than 50% of professional translation work. Nimdzi’s 2025 market report says 82.4% of surveyed language companies offer machine translation and post-editing. We think those two numbers explain the mood of the market better than any model benchmark does. AI is no longer a side experiment. It is part of the production environment, whether translators asked for that or not.
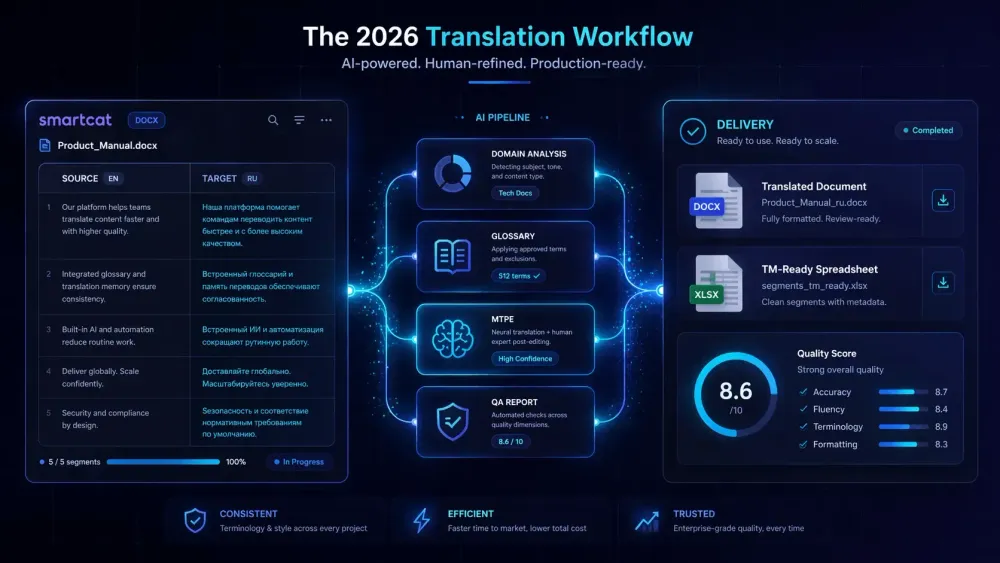
We built SnapIntel around a narrow version of that problem: Smartcat bilingual DOCX goes in, domain analysis and glossary control happen before translation, then the user gets a translated DOCX, a TM-ready spreadsheet, and a QA report out. That shape matters because the real issue in 2026 is not “can AI translate?” The real issue is whether a translator can keep control of terminology, repetition, review, and handoff while still moving faster.
Why AI translation tools now sit inside the normal workflow
The market data has stopped sounding speculative. The European Language Industry Survey 2025 reports that machine translation is used in more than 50% of professional translation work. The 2025 Nimdzi 100 says 82.4% of surveyed language companies provide machine translation and post-editing. That tells us two things. First, MTPE is now ordinary. Second, the competitive pressure on translators is no longer abstract. Clients assume some form of AI will touch the workflow, even when the final file still needs a human eye on every page.
We have seen that change most clearly with agencies handling document-heavy jobs under rough deadlines. A legal agency we worked with did not ask whether AI could draft the file. They assumed it could. Their concern was whether the AI output would stay inside approved clause language, reuse the right segments from TM, and avoid drifting on terms that had already been signed off by the client’s counsel. In that environment, the translator’s role shifts from raw typing to controlled decision-making. The translator checks precedent, adjusts the glossary, reviews repeated segments, and decides what still needs full human translation rather than post-editing.
CSA Research’s 2025 trends report adds another layer. It points to wider use of automated quality estimation and automated post-editing. We think that trend is real, but it does not reduce the need for human review. It changes where human effort should go. In a mature workflow, the question is no longer “human or AI?” It is “which parts are safe for AI, which parts need MTPE, and which parts should never leave human hands?” That is a production question, not a philosophical one.
Why the translator’s work is moving upstream
The best translators we know spend less time staring at a blank target segment than they used to. They spend more time shaping the conditions around translation. That means domain analysis, term selection, prompt rules, TM cleanup, and review strategy. The work is still linguistic. It is just happening earlier in the pipeline.
A freelance translator we know uses Smartcat bilingual DOCX files for technical material from mining and energy clients. Her main complaint is not that AI makes obvious mistakes. Her complaint is that AI often makes subtle ones. A term for a component will shift halfway through a manual. A repeated safety warning will sound slightly softer on page 47 than it did on page 3. A number will stay correct while the unit formatting changes. Those are the kinds of errors that survive a quick skim because the sentence still reads smoothly. In her words, AI has made “boring consistency” more important, not less.
That matches Smartcat’s own documentation. Smartcat’s Help Center explains that translation memory stores previously confirmed segments, glossary entries enforce approved term choices, and QA checks flag issues such as punctuation, spelling, terminology, formatting, and consistency with TM. In other words, the CAT tool still matters because fluency alone is not the metric that decides whether a translation is fit for delivery.
We think this is where some commentary about AI and translation misses the point. When people say translators are becoming editors, they often make it sound like the job is shrinking. In practice, the job is getting redistributed. A translator who can handle MTPE well is making judgment calls about risk, client style, domain language, and final usability. Those are not clerical tasks. They are the parts that clients usually notice only when they go wrong.
Why AI translation tools still depend on CAT tool discipline
A strong model helps. A weak workflow ruins the gain. We have become more convinced of that with every real file we have seen. AI translation tools do their best work when they are forced to behave inside a CAT workflow that already has rules for TM, glossary usage, segmentation, review, and export.
Smartcat is a good example of why that structure still matters. According to Smartcat’s Help Center, translation memories retrieve exact and fuzzy matches from previously confirmed segments, while glossary matches offer approved terms when the system detects them in the source text. Smartcat also says a file with repetitions and fuzzy matches can save almost 40% on translation costs. That is old CAT-tool logic, but it still drives the economics of AI-assisted translation in 2026.
We saw this very clearly in a medical device instructions project. The raw AI output looked fine at sentence level. The problem came from repetition management. The file reused the same warning language across multiple sections, with small differences depending on device configuration. Without TM discipline, the output started sounding polished but inconsistent. Once the team treated the file as a CAT job instead of a chat prompt, the quality improved fast. Exact matches were reused properly. The glossary was cleaned up. Segments that carried regulatory weight were reviewed in full. The final result was less glamorous and far more usable.
This is one reason we built SnapIntel around Smartcat bilingual DOCX rather than around generic document upload. The file already has structure. The translator already has a workflow. The useful move is not to ignore that structure. It is to preserve it, add domain analysis and prompt control before translation, and return deliverables that can go back into the working CAT environment without manual repair.
What Smartcat bilingual DOCX changes in practice
Bilingual files do not solve everything, but they remove a lot of avoidable mess. Smartcat’s own blog describes bilingual files as a way to keep source and target text side by side for translation and review, while Smartcat’s documentation explains how TM, glossary suggestions, and QA sit around that workflow. We think that matters more in 2026 because many AI-first setups still break at the handoff stage. The text gets translated, but the review path gets messy, and the value of the CAT environment gets lost.
A lot of agencies already know this pain. They export content, run outside translation steps, paste results into side spreadsheets, and then spend extra time rebuilding the file into something a reviewer can actually inspect. That kind of process feels fast on the first test. It often becomes slow once the project involves multiple files, repeated segments, and a client who notices terminology drift.
With Smartcat bilingual DOCX, the handoff is much cleaner. The file already reflects the translation unit structure that the linguist is working with. That makes it easier to run domain analysis before translation, generate a project glossary, and keep the prompt tied to the actual job rather than to a vague description. In our experience, that is especially useful for agencies that handle recurring client work. One batch of Smartcat exports can reveal the client’s terminology habits faster than a generic source document can.
This is also why we think “AI translator” is too loose a category for serious buyers. The real question is what happens before and after the model runs. If the tool helps the translator prepare the job, preserve the file structure, and produce outputs that support QA and TM updates, it is doing real work. If it only generates text, the translator still has to solve the operational problem alone.
Where the pressure is real for translators and agencies
There is no honest way to write about AI translation tools in 2026 without talking about downward price pressure. The Society of Authors’ 2024 survey found that 37% of translators had used generative AI in their work, 36% had already lost work because of it, and 43% said their income had decreased in value because of generative AI. Those figures come from a different part of the language world than enterprise localization, but the anxiety they reflect is familiar.
We hear the same tension from agencies. Clients want faster turnaround and often assume AI should lower the rate by default. At the same time, they still expect translators to catch terminology errors, preserve formatting, maintain client style, and explain why the final text can be trusted. That gap is where a lot of resentment now lives. Buyers want “AI speed” while still asking for human accountability.
We think the only durable response is to make the workflow explicit. Do not sell mystery. Sell the method. If a project is being handled as MTPE, say so. If glossary creation, domain analysis, and QA review are part of the process, say so. If certain content types are excluded from AI-first treatment, say so. Ambiguity helps nobody except the client who wants a lower quote without understanding what is being cut.
This also means translators need to price the work that now sits around the model. In many projects, glossary curation, QA review, terminology cleanup, and segment-level post-editing are the actual service. The model is just one step in the chain. We would argue that agencies that fail to explain that will have a harder time defending rates than agencies that show clients the production logic in plain language.
What a workable 2026 setup looks like
The teams getting good results from AI translation tools are usually boring in the best way. They standardize the workflow. They decide which files go through MTPE, which files need full human translation, and which files require a domain-specific glossary before anything starts. They do not treat prompting as magic. They treat it as one controlled input.
A workable setup usually has five parts. First, the source file enters through a CAT-friendly path, not through copy-paste chaos. Second, the translator or project manager runs domain analysis and prepares the glossary. Third, AI translation happens with those constraints already in place. Fourth, QA catches terminology, number, punctuation, and formatting issues. Fifth, the results come back in a form that supports review and future TM use. That is basically the logic we followed in SnapIntel’s product spec, because it reflects how real document teams already work.
Two places where we think teams still get it wrong
The first is over-trusting fluent output. A segment can read well and still be wrong for the client, wrong for the domain, or wrong for the TM. The second is under-valuing the return path. If the translator cannot review the file cleanly, share a QA report, or feed approved segments back into memory, the time saving will often evaporate on the next job.
Our advice is very practical. Take one recurring file type, ideally something with repetition and terminology pressure. Run it through a controlled MTPE workflow. Use Smartcat bilingual DOCX. Build the glossary first. Review the QA report seriously. Then compare the result against your current process, not against fantasy. If it saves time and still protects trust, expand from there. If it does not, change the workflow before you blame the translator or praise the model.