Data Privacy in AI Translation: What Agencies Need to Tell Their Clients
What translation agencies need to know about ai translation data privacy: GDPR obligations, data retention, DPA requirements, and what to tell clients.
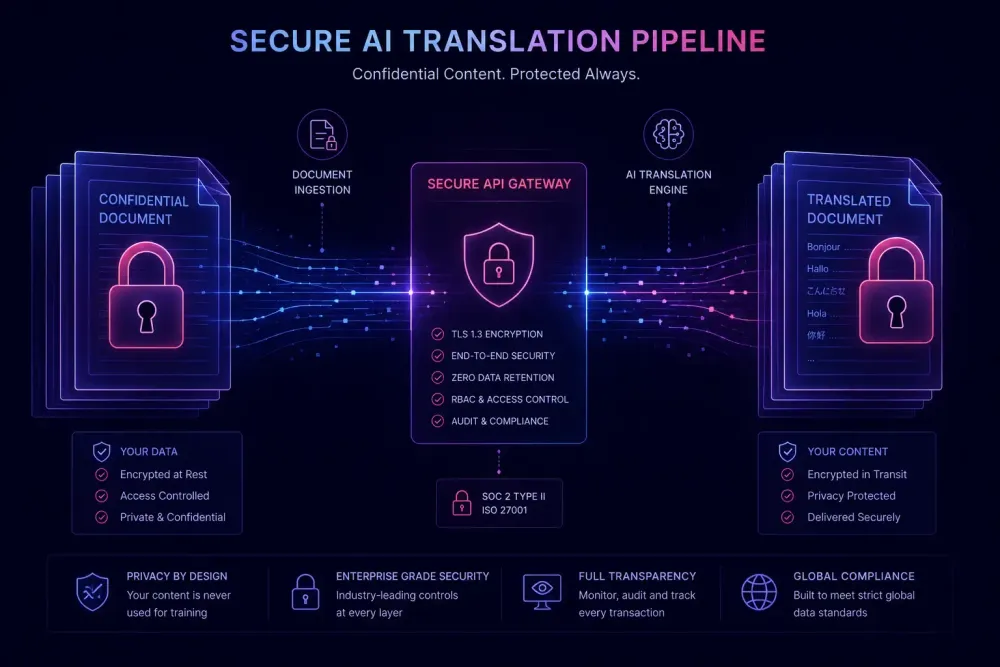
When a client sends you a confidential employment contract or a set of audited financials for translation, they're extending trust in a specific direction: to your team, your systems, your discretion. Using AI translation tools extends that trust further — to cloud APIs, third-party processing servers, and data retention policies your client has never read and you may not have either.
Most clients don't think about this until something prompts them to. Then they do, and they ask. If your answer is vague — or worse, confident but wrong — you have a problem that's harder to fix than the translation itself.
Over the past year, questions about ai translation data privacy have become standard due diligence for clients in legal, healthcare, and financial services. Legal departments, procurement teams, and compliance officers now routinely ask agencies to explain, in plain terms, what happens to their documents once they leave the client's servers. This article is about how to answer that question accurately — and how to build the practices behind it.
What clients are actually asking (and it's not what you think)
The question "what happens to our data?" usually isn't about catastrophic breach scenarios. It's about three more specific concerns.
The first is model training. Clients worry that content from their documents might be ingested into a language model and appear in someone else's output. This concern gained traction in 2023, when Samsung engineers accidentally submitted proprietary chip design information through ChatGPT, prompting Samsung to ban the tool internally. The incident was widely reported and reshaped how risk-conscious clients approach any AI tool that touches their content.
The second concern is jurisdiction. Clients with strict data residency requirements — common in healthcare, banking, and government contracting — want to know where processing happens. For GDPR-covered personal data, the jurisdiction of the AI provider matters.
The third is retention. How long does the API provider keep a copy of the translated text? Is it logged? Can it be accessed by the provider's staff?
None of these are irrational. They're the same questions any information security team would ask about a third-party data processor. The problem is that most translation agencies have adopted AI tools based on output quality and cost, without documenting the data handling chain that comes with them.
That gap is manageable. But closing it requires actually knowing which tools you're using, what settings you've configured, and what your providers' retention policies say. Start there.
GDPR and AI translation: where agencies tend to get it wrong
If you serve EU-based clients or process documents containing personal data from EU residents, GDPR applies to your work. Personal data appears constantly in translation projects: names in contracts, identifiers in HR files, health information in medical reports, account details in financial correspondence.
Two obligations matter most for agencies using AI translation tools.
The first is legal basis. You need to know your legal basis for processing personal data. For most translation work, this is contract performance — you're processing the data in order to deliver the service your client contracted — or, less commonly, legitimate interest. You don't need a written assessment for every project, but you should be able to articulate the basis if a client or regulator asks.
The second is transfers. Personal data can't be freely transferred outside the EEA without appropriate safeguards. Most major AI translation API providers maintain Standard Contractual Clauses and data processing addenda for exactly this reason. But those safeguards only apply if you've actually signed the relevant agreements. Having a commercial account with an API provider is not the same as having a signed data processing addendum with them.
The part agencies most often miss: if your client is the data controller and you're processing their data on their behalf, a Data Processing Agreement between you and your client is legally required under GDPR Article 28 — regardless of whether the client asks for one. Adding AI tools to your workflow means updating that DPA to reflect the new sub-processors involved.
Many agencies haven't touched their DPA templates since adopting AI tools. That's the most common gap we encounter.
How data actually moves through an AI translation workflow
Knowing the data lifecycle makes client questions easier to answer accurately, because you can trace exactly where their content goes.
A typical AI-assisted translation run works like this: the client shares a document by email or file transfer. Your team uploads it to a translation platform or directly to an AI tool. The tool segments the document into translation units and sends those units to one or more AI API endpoints. The API provider processes the request and returns translated text. The assembled document is reviewed if needed and delivered.
Each step has data handling implications. Segmentation means the document is in a different format, but the content is unchanged. The API call means the content has left your system and entered the provider's infrastructure. The retention period means a copy of that content may exist on a third-party server for some time after the job finishes.
Retention policies vary meaningfully across providers. OpenAI's API does not use inputs to train models and retains data for up to 30 days for abuse monitoring under standard settings; enterprise zero-data-retention configurations exist separately. Google Cloud Translation retains request data for up to 60 days under standard terms. DeepL Pro API does not store translation content after processing completes.
If you're using multiple tools across different parts of your workflow, you likely have inconsistent retention periods running alongside each other. A client asking "how long is our data retained?" deserves a real answer. That answer requires knowing specifically which API handled which document.
This is also where the distinction between consumer interfaces and API access starts to matter. A translator who copy-pastes content into ChatGPT.com is operating under different data handling terms than one making API calls through a configured integration — even if the underlying model is the same. These distinctions are hard for clients to understand without a clear explanation from you.
Building a client disclosure that actually holds up
The default move for many agencies is to write a privacy statement that's legally defensible but practically useless — vague enough to never be wrong. That approach tends to backfire.
Clients who receive a generic paragraph pointing to a privacy policy URL often ask more follow-up questions. Clients who receive a clear explanation of what your AI tools are, how data flows through your workflow, and what retention settings you've configured tend to ask fewer — because their actual concern has been addressed.
A useful data privacy disclosure covers four things: which AI services process client documents; what data handling settings you've configured on those services; what the relevant API provider's retention policy is; and what access controls prevent unauthorized parties from reaching the data.
The tone matters as much as the content. A disclosure that reads like it was written to preempt liability generates skepticism. One that reads like an honest account of how your tools work generates confidence. We've seen agencies win contracts specifically because they sent a clear, specific data handling explainer with their proposal — particularly with legal and financial services clients who deal with this kind of question regularly. Two pages written in plain language beats six pages of legal boilerplate.
For some clients, a written disclosure still isn't enough. They'll want a completed Data Processing Agreement before signing your contract. Having a DPA template reviewed by legal counsel isn't optional for agencies working in regulated sectors — it's part of the service.
One more thing worth noting: your disclosure should be updated when your tooling changes. An agency that adopted AI translation tools eighteen months ago and hasn't revisited its data documentation since is likely describing a workflow that no longer matches reality. Clients who later discover the gap won't forget it.
For broader context on how AI tools are changing translation agency workflows, we've covered this in more depth in a recent post.
Data Processing Agreements: what they cover and when you can't skip them
A Data Processing Agreement defines the relationship between a data controller (your client) and a data processor (your agency) when the processor handles personal data on the controller's behalf. Under GDPR Article 28, this agreement is required — not optional, not best practice, required.
For AI translation, the DPA needs to do two things that older templates often don't. First, it needs to accurately describe the processing activities: what data is processed, for what purpose, for how long. If you've updated your workflow to use AI tools, that description has changed and the DPA needs to reflect it. Second, it needs to list your sub-processors. Every AI translation API you use in delivering your service is a sub-processor.
Most major AI API providers have a sub-processor list and a data processing addendum available for signature. Signing those addenda puts the required legal relationship in place downstream. But your client-facing DPA also needs to reflect that these sub-processors exist, and most clients retain the right to be notified when you add a new one.
On timing: don't wait for a client to request a DPA. If you're working with EU-based clients or handling documents that contain personal data from EU residents, check your standard contract templates now. The DPA should be included by default, not sent over as an afterthought when a client's legal team asks for it.
Some agencies add a short AI tool disclosure as an exhibit to the DPA, listing current services and their retention policies. That approach keeps the agreement current without requiring a full redraft every time a tool changes — just an updated exhibit.
A practical boundary worth knowing: a DPA governs how you handle your client's data. It does not govern the relationship between you and your AI API providers; that's covered by the API provider's own data processing addendum, which you sign separately. Both need to be in place for the legal chain to be complete.
Practical controls that reduce exposure without slowing your team down
Beyond legal documentation, a few operational practices make a real difference in how much risk you're carrying.
Use API access rather than consumer interfaces for all project work. This is the single most effective control available to most agencies. Consumer-facing products like ChatGPT.com, browser-based Google Translate, and the free DeepL web interface have different — and often less protective — data handling terms than their API counterparts. An agency that restricts all translation work to API access has a consistent, documented data handling baseline. One that mixes API and consumer interfaces does not, and explaining the difference to an auditor or a client is difficult.
Configure the privacy settings that are available. Some AI translation APIs offer reduced retention periods or zero-data-retention modes that prevent any storage of request content beyond the immediate processing window. Where these settings exist and you're handling sensitive client work, they should be on by default, not treated as optional features.
Maintain a sub-processor register. This doesn't need to be complicated — a spreadsheet listing which AI services touch client data, their retention policies, and when you last reviewed their terms is enough. It takes under an hour to build and becomes the foundation for answering client and auditor questions accurately. Update it when you add or remove a tool.
For particularly sensitive documents — legal proceedings, health records, personally identifiable financial data — consider a tiered approach before anything reaches an AI workflow. Some agencies flag sensitive documents at intake and route them through a more controlled process, sometimes involving a human translator working in a more locked-down environment rather than through a third-party cloud API. That distinction is worth documenting in your client-facing materials if you offer it.
This works best when the intake process actually catches sensitive documents. If your project managers aren't briefed on what "sensitive" means for your purposes, the tier exists on paper but not in practice.
When a client says they don't want cloud processing
This objection comes up most often in legal, healthcare, and public sector work. It's worth having a prepared answer rather than an improvised one.
Start by clarifying what the client actually means. "No cloud processing" sometimes means they don't want their data used for model training — a concern addressed by API access with appropriate settings, not by avoiding cloud infrastructure entirely. Other times it means data has to be processed within a specific jurisdiction: a data residency requirement that needs a different answer, one that involves checking whether your API providers can guarantee in-region processing for the jurisdictions your client requires.
In some cases, the objection means exactly what it sounds like. The client has a policy against any processing outside their own infrastructure. Most cloud-based AI translation services can't satisfy that without a custom enterprise arrangement, and those arrangements are generally outside the pricing range of small and mid-sized agencies unless the client funds the setup directly.
If that's the situation, the honest answer is this: your AI translation service runs on third-party cloud infrastructure, you have strong contractual and technical protections in place, but fully on-premise AI processing is not part of your current service offering. Some clients will accept that. Others won't. Knowing your actual capabilities before the conversation saves everyone time.
What doesn't help is trying to reframe the objection as something it isn't. If a client has a genuine data residency requirement and your infrastructure can't satisfy it, the right move is to say so clearly, explain what you can offer, and let them decide. Agencies that oversell their data handling capabilities to close a contract tend to encounter the same client again, under worse circumstances, when the gap becomes apparent.
Three steps address most of what clients will ask about ai translation data privacy. Audit your current AI tool list and document the retention policy for each one. Review your DPA template to confirm it covers AI sub-processors accurately. Draft a plain-language data handling disclosure you can send proactively — before a client raises the question.
None of this requires a legal background. It requires knowing what's actually happening in your own workflow. Clients raising data privacy questions aren't being obstructionist; they're asking a reasonable question about a tool your agency chose to use. Being ready with an accurate, specific answer is the professional baseline — and in regulated sectors, it's increasingly a prerequisite for getting the project in the first place.