Adaptive machine translation explained: how MT that learns from your corrections works
Adaptive machine translation learns from your post-editing corrections to improve future output. Here's how it works and when it's worth using in your workflow.
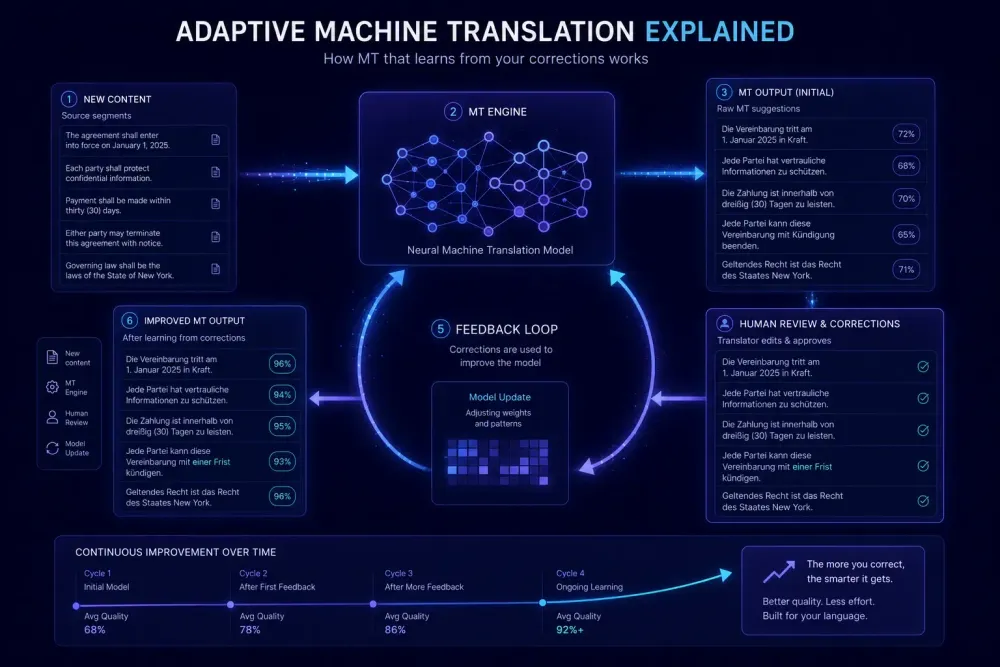
Adaptive machine translation has been discussed in the industry for years, but the practical reality of how it works remains unclear for many translation teams. The basic idea is appealing: instead of getting the same quality output every time regardless of your corrections, the MT engine learns from how you edit its suggestions and produces better matches in future jobs. Whether that promise holds up in a real agency workflow depends on specifics that vendor marketing rarely addresses.
What adaptive machine translation actually is
Standard neural machine translation (NMT) engines like the models behind DeepL, Google Translate, or most LLM-based systems are trained on large datasets and then deployed as fixed models. Every segment you translate goes through the same model weights regardless of how many times you've corrected a terminology error or adjusted a register problem. The output quality on job 100 is the same as on job 1, assuming the model hasn't been updated by the vendor.
Adaptive MT changes this by building a feedback mechanism into the translation pipeline. When a post-editor corrects an MT output, that correction is captured and used to update the system's behavior for subsequent segments, either within the same document or across future projects. There are two distinct mechanisms commonly called "adaptive MT" that are worth separating.
Online adaptation means the model receives correction signals during the current session and adjusts its output immediately. You correct a segment early in a document, and the engine applies what it learned when it encounters similar content later in the same file.
Incremental learning is slower: corrections accumulate in a feedback dataset and are periodically used to update a fine-tuned version of the base model. This approach produces more durable improvements, but the effect takes time to surface.
Not every system marketed as "adaptive" does both. Some products do basic TM-assisted pre-translation and label it adaptive because the TM grows as you add entries. That's a different mechanism entirely.
The feedback loop: how your corrections teach the engine
In a genuine online adaptive MT system, the post-editor's changes generate training signals that influence subsequent output. When you change "undertake" to "complete" in a legal contract, the system notes that relationship in context and applies similar substitutions when it encounters analogous phrases later in the file.
The main limitation here is context specificity. Adaptation is most effective within the same document or project, where stylistic and terminological patterns repeat. If you're translating a 40-page technical specification where the source uses a specific phrase for a product feature 30 times, correcting the first instance typically propagates across the rest of the document. That's the scenario where you see a real productivity gain.
Outside that document, the benefit degrades unless the system supports cross-document or cross-project learning. Some enterprise-grade systems build adaptive layers on top of domain-specific models, so corrections in a legal project accumulate into an improved legal model over time. That approach requires significant correction volume to produce measurable improvement, usually thousands of corrected segments per domain.
We've seen agencies run adaptive MT pilots expecting improvement from day one, segment by segment. The actual curve is more gradual: within a document, you notice it; across a project, it's visible; across months of consistent corrections, it becomes a meaningful quality difference versus a static baseline.
Adaptive MT vs. static neural MT: what changes over time
The most common question we hear is: if I use a static NMT engine paired with a well-maintained translation memory, what am I actually missing by not using adaptive MT?
The difference shows up most clearly with client-specific terminology and tone. A static NMT engine with a glossary can enforce approved term translations when the system detects a match, but it has no mechanism to learn that this client prefers a particular register in technical contexts, or that a specific phrase always gets edited to something shorter. Those patterns only get captured if you move corrections back into a glossary or TM manually.
An adaptive engine theoretically absorbs those preferences from the correction stream without requiring manual curation. In practice, the quality of that learning depends on how the feedback is structured. If post-editors correct for different reasons (one fixes terminology, another adjusts register), the signals can conflict and produce inconsistent adaptation.
What we've observed across different deployments: static NMT with a well-structured glossary and a high-quality TM will outperform a poorly configured adaptive system. The adaptation mechanism is only useful if you have a consistent post-editing process producing clean, coherent correction signals.
Where translation memory ends and adaptive MT begins
TM and adaptive MT are often conflated, but they solve different problems. A translation memory stores previously translated and confirmed segments and retrieves exact or near-exact matches for reuse. It doesn't change what the MT engine produces for new, non-matching content.
Adaptive MT affects what happens when there is no TM match. It changes the base translation the engine produces for new content by incorporating learned patterns from previous corrections.
In a typical workflow, both run in parallel. A segment comes in, the system checks the TM for a match. If there's a high-confidence match (typically 95–100%), it's applied automatically. If there's a fuzzy match (75–94%), it's suggested but the post-editor decides. If there's no match, the MT engine produces output, and the adaptive component influences what that output looks like.
The two systems complement each other, but they can also interfere. If your TM contains outdated or inconsistent entries, those poor matches may override MT output that would actually be more accurate. We've seen projects where teams disabled TM pre-translation for certain content types precisely because TM quality was dragging down an otherwise solid MT output.
Maintaining clear boundaries between what gets stored in TM, what goes into the glossary, and what should feed adaptive learning is ongoing maintenance work. That overhead is part of what makes adaptive MT setups harder to evaluate on short pilot timescales.
When adaptive MT genuinely helps (and when it doesn't)
Adaptive MT shows consistent benefit in specific scenarios. Long, repetitive documents with consistent terminology — technical manuals, product documentation, legal contracts where specific entities are named throughout — are where within-document online adaptation produces measurable post-editing time savings. In one deployment we reviewed involving a software localization team, post-editing speed on repeat-heavy UI documentation improved by around 20% after the first 15 pages, as the adaptive engine had absorbed the client's naming conventions from early corrections.
Ongoing projects with stable post-editing teams are another case where it performs well. When the same translators work consistently on the same client's content over time, and their editing signals are coherent, cross-project learning has something meaningful to work from. The benefit compounds gradually rather than appearing immediately.
The cases where adaptive MT doesn't help much: short-form varied content like press releases or social media posts, multilingual projects where different post-editors contribute corrections for the same domain in different languages, and projects where post-editing quality control is inconsistent and introduces noise into the feedback signal.
This doesn't apply if you're working with content types that change significantly in structure and vocabulary from project to project. Generic NMT without an adaptive layer is often entirely sufficient in those situations, and the added complexity of managing adaptation isn't worth the overhead.
How to evaluate adaptive MT claims from vendors
Most MT vendors now describe their systems as adaptive in some form. Evaluating what's actually under the hood requires asking specific questions rather than accepting marketing language.
Ask about adaptation scope: does the system adapt within documents only, or does it carry corrections forward across projects? Systems that only adapt within a session are useful for long documents but deliver no compounding benefit across your ongoing client work.
Ask about the learning mechanism: is adaptation handled by the MT engine itself through weight updates, or is it simulated by populating a TM and glossary from corrected segments? The second approach can be useful, but it's not what's typically meant by adaptive MT, and it requires you to maintain those resources explicitly.
Ask about measurement: can the vendor show you quality improvement curves from comparable deployments? Claims without data don't help you make a workflow decision. Reputable vendors can show before/after post-editing productivity numbers from real customer use, broken down by content type and language pair.
For translation agencies evaluating AI tools more broadly, the article on how AI translation tools are changing the way translators work covers where adaptive MT sits relative to other AI-assisted approaches in the current market.
Practical steps to get real benefit from adaptive MT
If you're implementing adaptive MT or evaluating whether to switch to a system that supports it, a few things make the difference between a useful feedback loop and one that degrades over time.
Standardize your post-editing process first. Adaptive learning produces reliable output only when correction signals are consistent. If different post-editors make different choices for identical content, the system receives conflicting signals and adaptation becomes unreliable. Before feeding corrections into an adaptive system, agree on your style guide, terminology reference, and what constitutes an acceptable vs. unacceptable MT output. Corrections for genuine errors (wrong terminology, mistranslated meaning) should be tracked separately from subjective style preferences.
Separate the test set from the training signal. A common mistake in MT evaluation is post-editing the same content that feeds back into the learning system, then comparing output quality before and after. You need a held-out test set, documents not used for training, to measure whether the system is actually improving or just memorizing your test content.
Track post-editing time, not just error counts. Adaptive MT's main value proposition is productivity: fewer keystrokes, faster post-editing per word. Segment error counts are a useful proxy, but the metric that matters to your agency's unit economics is time per word. Build that measurement into your workflow evaluation before committing to a platform.
For teams looking to add structure to AI translation without building feedback loop infrastructure, SnapIntel takes a different approach: glossary and prompt controls are built into the preparation step before any translation job starts, so terminology and instruction grounding are in place from the first segment. That won't replace adaptive learning at scale, but for agencies translating DOCX and XLSX documents who want consistent AI output without managing an ML pipeline, it's a practical option worth looking at.
The honest version of what adaptive MT delivers: it's a genuine improvement for the right content types, at the right scale, with the right team discipline around post-editing. For short, varied, or one-off projects, it adds overhead without proportional benefit. Matching the tool to the actual workflow is the real work.